




AIパイプラインに必要なGPUプラットフォームの選び方をご紹介
【AIパイプラインにおける3つの課題を解説】
・適切なインフラ構築に対する不安
・費用対効果の不透明性
・担当者の専門的知識
◆CPUだけで十分?GPUの必要性が分からない・・
◆GPUアクセラレーターだけではなく、ストレージ/ネットワークを含めた設計、構築が不安
◆大型投資はどの程度の効果が見通せるのか、導入してみないとわからない
◆ハードウェアとソフトウェア(コンテナ管理やライブラリなど)の両方の知識が不足
このようなことでお困りの方は、是非カタログをダウンロードして詳細をご覧ください。
https://www.aperza.com/catalog/page/10008211/66075/
このカタログについて
| ドキュメント名 | AI開発者必見! AIパイプラインに最適なプラットフォームとは? |
|---|---|
| ドキュメント種別 | ホワイトペーパー |
| ファイルサイズ | 1.5Mb |
| 登録カテゴリ | |
| 取り扱い企業 | 東京エレクトロンデバイス株式会社 (この企業の取り扱いカタログ一覧) |
この企業の関連カタログ




このカタログの内容
Page1
AI開発者必見!
AIパイプラインに最適な
プラットフォームとは?
東京エレクトロン デバイス株式会社
Page2
製造業におけるAIの導入効果
前例のない量のデータが日々生成・収集される中、様々な企業で人工知能(AI)を活用したビジネス
変革への取り組みが進んでいます。国内製造業においても、製品やサービスの高付加価値化や業務効率
化に向けてAIの活用検討が活発になっています。
■製造業における代表的なAI活用用途
• 画像検査による良否判定の自動化
• 画像検査の精度向上
• 故障の検知と予防保全
• 需要予測
• 意思決定の自動化
$6,000万の追加年間利益を 検査漏れ率を64%削減 検査のスループットを2倍に改善
もたらす1%の歩留まり改善
コンピューティングリソースが課題に
企業のビジネスに変革をもたらすAIですが、いくつか検討すべき課題があります。
その内の一つが、巨大化するAIモデルの学習時間をいかに短縮できるか、という点です。
例えば生産ラインの良否判定の自動化において精度を向上させるためには、検査したい製品や
部品の画像を撮影し、正常品と不良品の仕分けをAIに覚え込ませる必要があります。
この学習フェーズにおいて、ディープラーニング(深層学習)が高い効果を発揮できる手法として
注目を浴びています。ディープラーニングは「データの中から特徴を見つけ出す」という特質上、
精度を向上させるためには、できるだけ多くのデータを取得して学習させる必要があります。
サイズの大きな画像や大量のデータを扱うため、従来のCPUの計算能力では数週間かけても学習が
終わらないというケースは珍しくありません。学習時間の長期化はAIモデル開発に掛るコストと
ビジネススピードの観点で軽視できない課題と言えます。
この課題を解消すべく、AI向けプラットフォームで標準採用されているのがGPU(グラフィックス
・プロセッシング・ユニット)です。
GPU活用によるAIモデル開発期間の短縮
GPUは元々3Dグラフィックスの描写の為に使われていましたが、大量の並列処理を得意として
いる特性から、AIの計算用途としても注目されるようになりました。
CPUでは1基数コア~数十コアですが、最新のGPUでは1基で数千のコアを搭載しています。
GPUは内部でコアが連携して動作することで並列処理が行えるため、CPUに比べて圧倒的な処理
性能を誇ります。行列計算の処理スピードにおいてはCPUの10倍以上とも言われ、スーパーコン
ピュータやHPC(high performance computing)といった科学研究の分野でも標準的に採用さ
れています。
加速するAI開発の裏には、ビッグデータを高速に処理するGPUの登場と進化があると言えます。
Page3
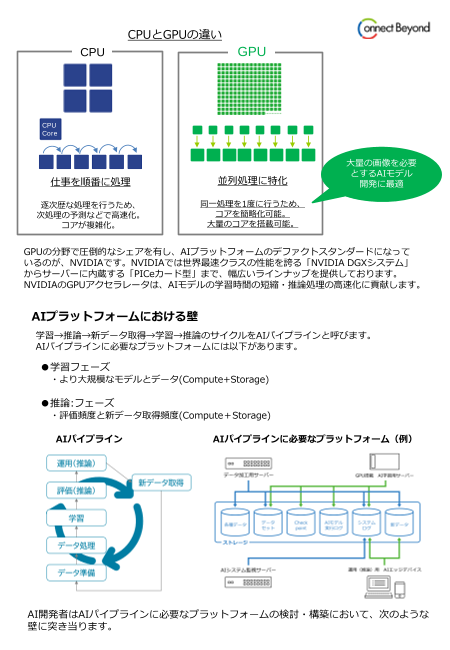
CPUとGPUの違い
CPU GPU
CPU
Core
大量の画像を必要
とするAIモデル
仕事を順番に処理 並列処理に特化 開発に最適
逐次歴な処理を行うため、 同一処理を1度に行うため、
次処理の予測などで高速化。 コアを簡略化可能。
コアが複雑化。 大量のコアを搭載可能。
GPUの分野で圧倒的なシェアを有し、AIプラットフォームのデファクトスタンダードになって
いるのが、NVIDIAです。NVIDIAでは世界最速クラスの性能を誇る「NVIDIA DGXシステム」
からサーバーに内蔵する「PICeカード型」まで、幅広いラインナップを提供しております。
NVIDIAのGPUアクセラレータは、AIモデルの学習時間の短縮・推論処理の高速化に貢献します。
AIプラットフォームにおける壁
学習→推論→新データ取得→学習→推論のサイクルをAIパイプラインと呼びます。
AIパイプラインに必要なプラットフォームには以下があります。
●学習フェーズ
・より大規模なモデルとデータ(Compute+Storage)
●推論:フェーズ
・評価頻度と新データ取得頻度(Compute+Storage)
AIパイプライン AIパイプラインに必要なプラットフォーム(例)
AI開発者はAIパイプラインに必要なプラットフォームの検討・構築において、次のような
壁に突き当ります。
Page4
#1 適切なインフラ構築に対する不安
GPUアクセラレータだけではなく、必要なデータを貯めておくためのストレージや、機器を接続する
ためのネットワークスイッチなどが必要となります。これらのインフラ全体を適切に設計、構築する
ことは簡単ではありません。
#2 費用対効果が見えない
AIアクセラレータへの投資を検討するにあたり、自社のAIモデル開発がどのくらい高速化されるを事前に確認する
ことが重要です。
#3 担当者に専門的な知識がない
プラットフォームの検討の際、ハードウェア(クラスタの管理や電力・冷却等)とソフトウェア
(コンテナ管理やライブラリのバージョン管理など)の両方に跨る幅広い知識が必要となります。
東京エレクトロンデバイスがAIプラットフォームの課題解決をお手伝いします!
AIモデルの開発やサービスの運用に必要な「AIアクセラレータ」「ストレージ」「ネットワーク」を
1つにまとめたのが、東京エレクトロンデバイス(TED)の「TED AIインフラパッケージ(TAIP)」
です。
精度の高いAIモデルを作成するには、膨大な学習を高速かつ効率的に繰り返す必要があります。
高速なアクセラレータが必要になるだけでなく、AIモデルの学習環境と推論(運用)環境を接続する
ネットワークやデータ共有の構成など、AI活用に特化した一連のシステムが必要です。
必要なコンポーネントを1つにまとめたTAIPなら、ユーザーは「学習データセット」と「AIモデル」を
準備するだけで即座にAI開発を始められます。
すべてTEDの取扱製品で構成されているため、導入からサポートまでワンストップで支援します。
✓ 最新のGPUアクセラレータを提供
✓ AIパイプラインを即座に利用可能
✓ ベンダーロックインの無い商品群
✓ 各製品のスペシャリストがお客様をサポート
✓ お客様の二ーズにそったカスタマイズ構成も可能
TED AIインフラパッケージ(TAIP)= プラットフォーム + サポート&サービス
Page5
世界最速レベルの環境をすぐに体験!TAILES
TAILES(TED AI Lab エンジニアリングサービス)は、世界最速レベルのAIアクセラレータの利用と
エンジニアサポートを併せたサービスです。TEDのエンジニアリングセンター(横浜市都筑区)にある
「TED AI Lab」で、すぐにディープラーニング等のPoC(概念実証)を実施いただけます。
✓ 大型モデルを試したみたいが、費用対効果がわからない
✓ 実データで試したいが、クラウド利用は禁止されている
✓ ハードウェアのチューニングに関する知見がない
✓ 機器の性能を試したい
これらのお悩みを即座に解決することが可能です。
大容量ストレージと高速ネットワークを従量課金なしで利用でき、ハードウェアの利用方法から
トレーニングまでTEDのエンジニアチームがサポートします。
TAILES ご支援内容
TED AI LAB 所在地
東京エレクトロンデバイス エンジニアリングセンター
〒224-0045 神奈川県横浜市都筑区東方町17番地
TEL:045-474-7005(代表)
東急東横線 大倉山駅より
横浜市営バス41系統「川向町」行または「中山駅前ららぽーと横浜」行で「東方町」下車
横浜市営地下鉄 新羽駅より
横浜市営バス41系統「川向町」行または「中山駅前ららぽーと横浜」行で「東方町」下車
JR横浜線 鴨居駅より
徒歩20分 ※タクシーの場合は小机駅または新横浜駅からご利用下さい。
当社の製品・サービスをご利用頂くことで、研究者の皆様はご自身の研究・開発に専念頂けます。
AIプラットフォームでお悩みをお持ちの方は是非お気軽にご相談ください。
【お問合せ】
https://cn.teldevice.co.jp/
〒163-1034 東京都新宿区西新宿3-7-1 新宿パークタワーS34階
Tel:03-5908-1990 Email: nvidia-presales@teldevice.co.jp